Hello 大家好!歡迎回來!昨天剛剛分享完時間序列分析 (Time Series Analysis),那今天我打算跟大家分享異常檢測 (Anomaly Detection)。事不宜遲,現在開始!
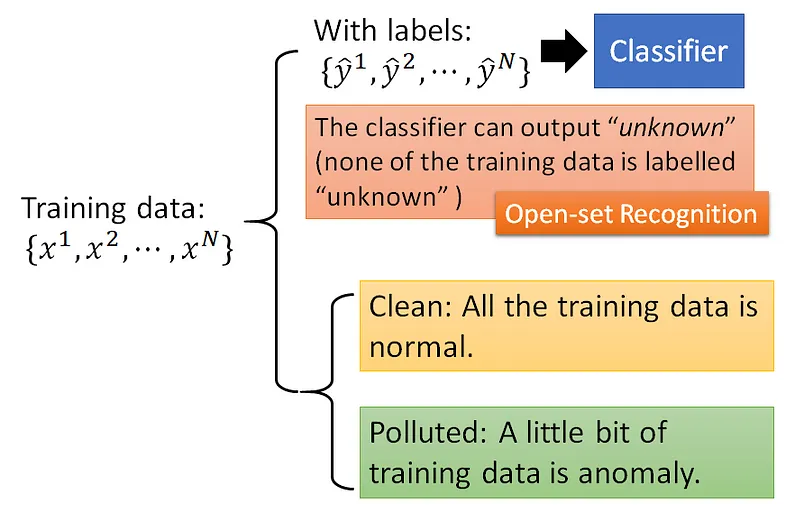
異常偵測是一種技術,用於識別數據集中與預期行為顯著偏離的模式或數據點。它在各個領域中扮演著重要的角色,如資訊安全、詐騙偵測、網絡監控和工業品質控制。異常偵測專注於識別數據集中的異常或不尋常觀察值。它涉及區分正常行為和異常行為,這可能暗示著潛在的問題、風險或機遇。
 [1]
[1]我是 Mr. cobble,明天見!


 iThome鐵人賽
iThome鐵人賽